ML model deployment in O-RAN
byRahul Kaundalon
Mapping ML functionalities into O-RAN control loops –
There are three types of control loops defined in O-RAN. ML assisted solutions fall into the three control loops. Time scale of O-RAN control loops depend on what is being controlled, e.g. system parameters, resources or radio resource management (RRM) algorithm parameters.
Loop 1 deals with per TTI msec level scheduling and operates at a time scale of the TTI or above.
Loop 2 operates in the near RT RIC operating within the range of 10-500 msec and above (resource optimization).
Loop 3 operates in the Non-RT RIC at greater than 500 msec (policies, orchestration). It is not expected that these loops are hierarchical but can instead run in parallel.
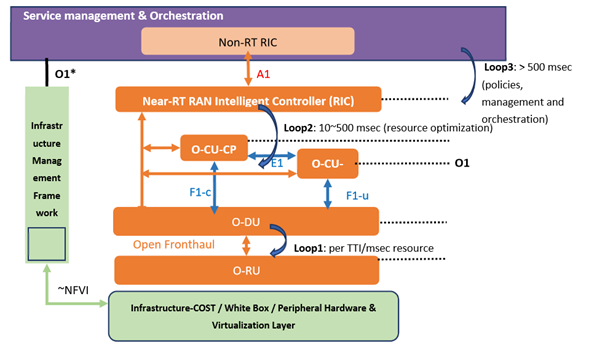
Control loops in ORAN (Source – ORAN Alliance)
The location of the ML model training and the ML model inference (model execution) for a use case depends on the computation complexity, on the availability and the quantity of data to be exchanged, on the response time requirements and on the type of ML model. For example, online ML model for configuring RRM algorithms operating at the TTI time scale could run in O-DU, while the configuration of system parameters such as beamforming configurations requiring a large amount of data with no response time constraints can be performed in the Non-RT RIC and Orchestration & management layer where intensive computation means can be made available.
ML General Procedure and Interface Framework –
ML is expected to be applied to any ML-assisted solution planned in O-RAN architecture. Any use case defined for ML-assisted solution shall have one or more phases (as applicable) and the phases are defined below:
1. ML model capability query/discovery – This procedure can be executed at start-up or run-time (when a new ML model is to be executed or existing ML model is to be updated). The SMO (System Management and Orchestration) will discover various capabilities and properties of the ML inference host, such as:
a) Processing capability of HW where ML model is going to be executed (for example: resources available such as CPU/GPU, memory etc. that can be allocated for ML model inference).
b) Properties such as supported ML model formats and ML engines (for example: Protobuf, JSON)
c) NFVI based architecture support in MF to run ML model
d) Data-sources available to run ML (for example: support for data streams, data lake, or any specific database access)
This discovery of the capabilities shall be used to check if a ML model can be executed in the target ML inference host (MF), and what number and type of ML models can be executed in the MF.
2. ML model Selection and Training – ML model is trained (refer previous document on ML for more details) and published in SMO catalogue.
3. ML model Deployment and Inference – The ML model that is selected for the use case can be deployed via containerized image to MF (Managed function) where ML model shall be executing. This also includes configuration of ML inference host with ML model description file. Once the ML model is deployed and activated, ML online data shall be used for inference in ML-assisted solutions, which includes:
a) 3GPP specific events/counters (across all different Managed Elements) over O1/E2 interface
b) Non-3GPP specific events/counters (across all different Managed Elements) over O1/E2 interface
c) Enrichment information from non-RT RIC over A1 interface
Based on the output of the ML model, the ML-assisted solution will inform the Actor to take the necessary actions towards the Subject. These could include CM changes over O1 interface, policy management over A1 interface, or control actions or policies over E2 interface, depending on the location of ML inference host and Actor.
4. ML model performance monitoring – The ML inference host is expected to feedback or report the performance of the ML model to the ML training host so that the ML training host can monitor the performance of the ML model and potentially update the model. Based on the use-case, specific set of data as applicable for use-case shall be used for ML model re-training. Based on the performance evaluation, either some guidance can be provided to use a different model in the ML inference host, or a notification can be sent indicating the need for retraining the model.
5. ML model redeploy/update – Based on the feedback and data received from various MFs, the ML performance evaluation module can inform the ML designer that an update is required to the current model. The ML designer will initiate the model selection and training step, but with the existing trained model. Once a new model has been trained, it will be deployed as described in Step 3, and the updated model will be used for ML inference.
ML Model Lifecycle Implementation –
Following are the steps involved in ML model lifecycle implementation –
1. ML Modeler uses a designer environment along with ML toolkits (e.g. scikit-learn, R, H2O, Keras, TensorFlow) to create the initial ML model
2. The initial model is sent to training hosts for training
3. The appropriate data sets are collected from the Near-RT RIC, O-CU and O-DU to a data lake and passed to the ML training hosts.
4. The trained model/sub models are uploaded to the ML designer catalog (one such open source catalog platform is AcumosAI). The final ML model is composed.
5. The ML model is published to Non-RT RIC along with the associated license and metadata.
6. Non-RT RIC creates a containerized ML application containing the necessary model artifacts (when using AcumosAI, the ML model’s container is created in Acumos catalog itself).
7. Non-RT RIC deploys the ML application to the Near-RT RIC, O-DU and O-RU using the O1 interface. Policies are also set using the A1 interface.
8. PM data is sent back to ML training hosts from Near-RT RIC, O-DU and O-RU for retraining.
Note that Near-RT RIC can also update ML model parameters at runtime (e.g., gradient descent) without going through extensive retraining. Training hosts and ML designers can also be part of Non-RT RIC.
ML Model Lifecycle (Source – ORAN Alliance)
Reference – ORAN alliance
